
Die hohe Parallelität der Datenbank war ein Problem, das das Datenbankpersonal verwirrte. Wie löst man das Problem der hohen Parallelität der Datenbank?
Die folgenden Methoden können gleichzeitige Operationen mit großen Datenmengen verarbeiten.
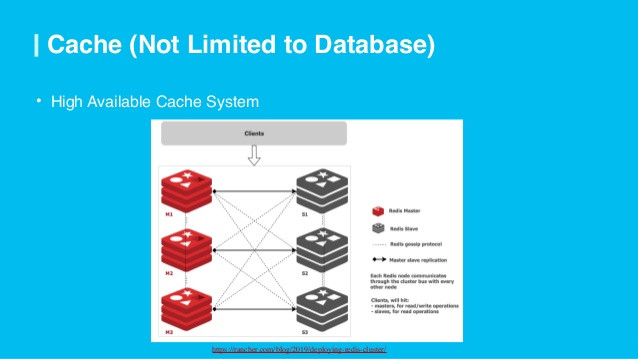
1. Cache verwenden
Verwenden Sie das Programm, um es im Speicher zu speichern. Verwenden Sie ein Caching-Framework. Speichern Sie es mit einem bestimmten Typwert, um leere Daten von nicht zwischengespeicherten Zuständen zu unterscheiden.
2. Datenbankoptimierung
Es gibt Optimierung der Tabellenstruktur und Optimierung von SQL-Anweisungen. Es gibt Syntaxoptimierung und Optimierung der Verarbeitungslogik. Sie können gespeicherte Prozeduren verwenden.
3. Trennung aktiver Daten
Es kann in aktive Benutzer und inaktive Benutzer unterteilt werden.
4. Stapellesen und verzögerte Änderung
Hohe Parallelität kann mehrere Abfrageanforderungen zu einer zusammenführen. Im Cache können hochgradig gleichzeitige und häufig geänderte gespeichert werden.
5. Trennung von Lesen und Schreiben
Es sind mehrere Datenbankserver konfiguriert. Konfigurieren Sie Master-Slave-Datenbanken. Die Masterdatenbank wird zum Schreiben verwendet. Zum Lesen wird die Slave-Datenbank verwendet.
6. Verteilte Datenbank
Speichern Sie verschiedene Tabellen in verschiedenen Datenbanken. Legen Sie sie auf verschiedene Server.
Um die Konsistenz und Integrität der Datenbank sicherzustellen, werden viele Tabellenzuordnungen entworfen. Beispielsweise können wir die Region in einer separaten Regionstabelle speichern. Bei geringer Datenredundanz kann die Integrität der Daten gewährleistet werden. Auf diese Weise wird die Datendurchsatzgeschwindigkeit verbessert. Die Integrität der Daten ist gewährleistet. Ordnen Sie einer untergeordneten Tabelle kein selbsterhöhendes Eigenschaftsfeld als Primärschlüssel zu. Dies ist für die Systemmigration und Datenwiederherstellung nicht bequem.
Bei der Gestaltung von Tabellen müssen Sie auf die spezifischen Aspekte achten.
1. Die Länge der Datenzeilen sollte Byte nicht überschreiten. Wird diese Länge überschritten, belegen die Daten auf der physischen Seite zwei Zeilen. Dies führt zu einer Speicherfragmentierung und verringert die Abfrageeffizienz.
2. Mit dem Feld Nummerntyp können Sie den Nummerntyp auswählen. Felder vom Typ Zeichenfolge verringern die Abfrage- und Join-Leistung und erhöhen den Speicheraufwand. Die Engine verarbeitet Abfragen und verkettet jedes Zeichen in der Vergleichszeichenfolge nacheinander. Für den digitalen Typ reicht nur ein Vergleich.
3. Sowohl der unveränderliche Zeichentyp char als auch der variable Zeichentyp VARCHAR sind Bytes. Char-Abfragen sind schnell, verbrauchen jedoch Speicherplatz. VARCHAR-Abfragen sind langsam, sparen aber mehr Speicherplatz. Bei der Gestaltung der Felder können Sie flexibel wählen. Beispielsweise kann CHAR für Felder ausgewählt werden, die sich in der Länge nur wenig ändern, wie beispielsweise Benutzername und Kennwort. VARCHAR kann für Felder mit gleicher Kommentaränderungsgröße ausgewählt werden.
4. Die Länge des Feldes sollte kurz sein. Dies kann die Effizienz der Abfrage verbessern. Beim Erstellen von Indizes kann es den Ressourcenverbrauch reduzieren.
Oben sind die detaillierten Schritte und Methoden aufgeführt, um die hohe Parallelität der Datenbank zu lösen. Ich hoffe, diese Methoden können Ihnen helfen.